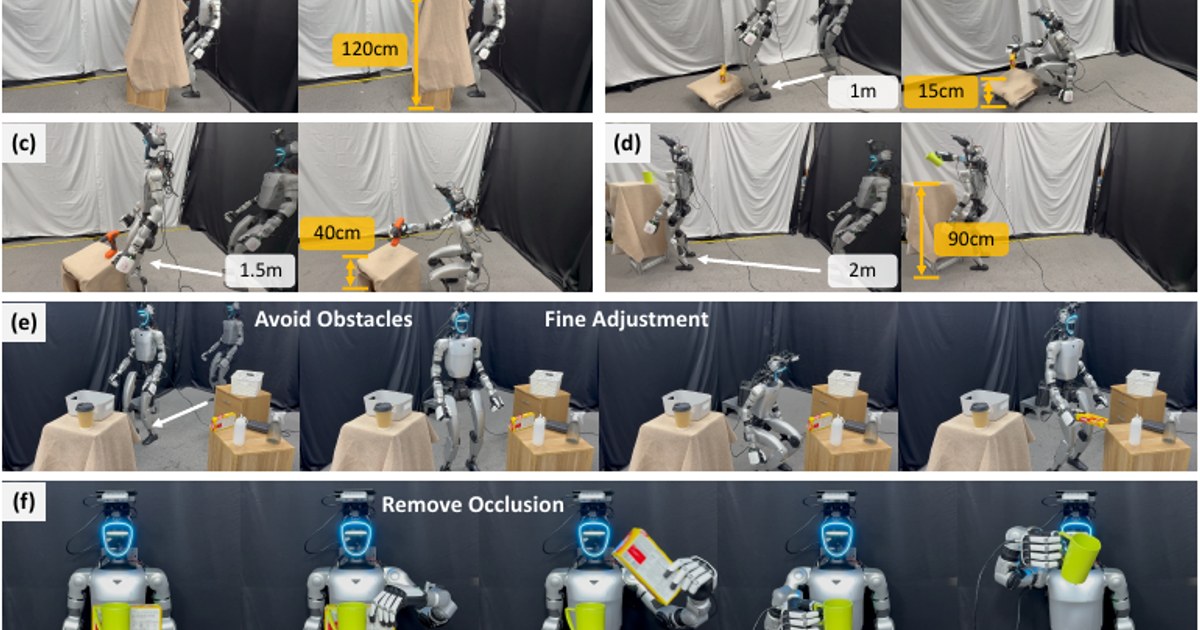
La manipulación humanoide de cuerpo completo está chocando con un problema menos vistoso que caminar o levantar cajas: entender el espacio antes de actuar. Un nuevo trabajo en arXiv, Active Spatial Brain and Generalizable Action Cerebellum, propone separar esas dos piezas para que el robot no dependa tanto de datos reales específicos de cada tarea.
El paper, publicado el 20 de mayo de 2026, no presenta un producto ni una plataforma comercial. Su interés está en la arquitectura: un módulo dedicado a percepción espacial activa, el Active Spatial Brain, y otro orientado a convertir esa comprensión en acciones ejecutables, el Generalizable Action Cerebellum. La tesis es clara: para que un humanoide manipule en entornos reales, no basta con mapear una escena estática ni con imitar trayectorias. Tiene que decidir qué mirar, cómo moverse alrededor del entorno y cómo usar todo el cuerpo para que la acción sea viable.
Del ojo pasivo al cerebro espacial activo
Muchos sistemas de manipulación robótica funcionan razonablemente bien cuando el escenario está acotado: una mesa, objetos visibles, cámara fija, brazo situado en una posición cómoda y una tarea repetida muchas veces. Esa configuración sirve para investigar, pero se queda corta cuando el robot debe operar como un humanoide móvil en una habitación, un taller o una vivienda.
La propuesta del paper intenta atacar justo ese salto. El Active Spatial Brain no se limita a reconstruir la escena a partir de una observación inicial. Según los autores, evalúa incertidumbre, selecciona nuevas vistas y construye una representación espacial más útil para la tarea. Dicho de forma sencilla: antes de mover la mano, el robot decide si necesita mirar mejor.
Ese detalle importa porque muchos fallos en robótica no empiezan en el control motor, sino en una percepción incompleta. Un objeto puede estar parcialmente oculto, una puerta puede abrir hacia un lado inesperado, una superficie puede quedar fuera del campo de visión o una trayectoria puede parecer libre hasta que el robot cambia de postura. En manipulación de cuerpo completo, la percepción y el movimiento no son fases separadas; se condicionan constantemente.
Un cerebelo de acciones generalizables
La segunda mitad del sistema, el Generalizable Action Cerebellum, aborda la parte ejecutiva. El objetivo no es aprender una política cerrada para una sola tarea, sino generar acciones que puedan trasladarse a situaciones nuevas sin requerir datos reales por cada escenario. El paper subraya esa idea: busca manipulación de cuerpo completo sin depender de demostraciones reales específicas de la tarea.
Es una promesa relevante, pero conviene leerla con cuidado. En humanoides, el coste de recopilar datos reales es alto: hace falta hardware caro, seguridad, supervisión, tiempo de operación y tolerancia a fallos. Si una arquitectura reduce esa dependencia, puede acelerar el entrenamiento y la adaptación. Pero eso no elimina la necesidad de pruebas físicas. Los modelos que parecen sólidos en simulación o en bancos concretos suelen mostrar sus límites cuando cambian fricción, iluminación, geometría, latencia o desgaste mecánico.
El interés técnico está en cómo el trabajo une percepción activa y acción. La mayoría de demos llamativas enseñan el resultado final: el robot abre algo, recoge algo o coloca algo. Lo difícil es la cadena intermedia: elegir dónde situarse, mirar desde un ángulo útil, ajustar el torso, mantener equilibrio, planificar contacto y corregir cuando la primera suposición falla. Ahí es donde la manipulación humanoide se diferencia de un brazo industrial bien fijado a una mesa.
Un avance de investigación, no un despliegue
El paper encaja en una línea de investigación más amplia sobre datos humanos y control generalizable para humanoides. Trabajos recientes como HuMI exploran cómo aprovechar interacción humana multimodal para enseñar manipulación, mientras que BifrostUMI aborda la construcción de datos cruzando humanos y robots con hardware portátil. Todos apuntan al mismo cuello de botella: conseguir que el aprendizaje robótico salga de tareas aisladas y se acerque a comportamientos reutilizables.
La diferencia de Active Spatial Brain and Generalizable Action Cerebellum está en poner la percepción activa en primer plano. No trata la cámara como un sensor que simplemente entrega datos, sino como parte de la política del robot. Para humanoides, esa idea es especialmente importante porque el cuerpo entero puede convertirse en herramienta de percepción: acercarse, rodear un obstáculo, inclinar el torso o reposicionar la base cambia lo que el sistema sabe del mundo.
Eso no significa que estemos ante una solución lista para fábricas o hogares. Es un preprint de arXiv y debe leerse como investigación. Faltan validaciones independientes, comparativas operativas y detalles que solo aparecen cuando el sistema se prueba durante horas en hardware real. También queda por ver cómo escala ante objetos deformables, interacción con personas, seguridad funcional o tareas donde un error físico tiene coste alto.
Por qué importa ahora
La robótica humanoide vive un momento extraño: hay más hardware disponible, más modelos fundacionales y más dinero que hace unos años, pero la utilidad real sigue estando limitada por tareas de manipulación robusta. Caminar ya no basta. El valor estará en robots que entiendan el espacio, actúen con todo el cuerpo y se recuperen cuando el entorno no encaja con la demo.
En ese contexto, este tipo de arquitectura es útil porque baja el debate de la promesa general al problema concreto. No pregunta solo qué modelo entiende una instrucción, sino qué información espacial necesita el robot para ejecutar una acción física. Esa pregunta, menos espectacular que otro vídeo viral, es probablemente una de las que separa la IA física de laboratorio de la robótica que algún día pueda trabajar fuera de él.
Fuentes
- arXiv — Active Spatial Brain and Generalizable Action Cerebellum for Humanoid Whole-Body Manipulation [en]
- arXiv — HuMI: Learning Generalizable Humanoid Manipulation from Human Interaction [en]
- arXiv — BifrostUMI: Modular, Lightweight, and Scalable Platform for Cross-Embodiment Dexterity Data Construction [en]
- Imagen: figura 1 del paper Active Spatial Brain and Generalizable Action Cerebellum [en]